The Rise of Diversity in Biomedical Research
This project with Catherine Lee (Rutgers Sociology) uses computational text analysis and word embeddings to study the use of diversity and population terms in ~2.6M biomedical abstracts from 1990-2020
sts race nlp viz ethicsKramer, B. & Lee, C. “The Rise of Diversity and Population Terminology in Biomedical Research” In Progress. [Project Website] [GitHub Repo]
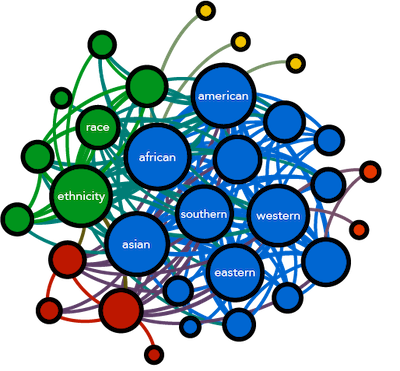
Recent scholarship has highlighted the rise of “diversity projects” across various educational and business contexts, but few studies have detailed what the discourse of diversity does within biomedical research. In this paper, we employ computational text analysis to examine quantitative trends in the use of various forms of diversity and population terminology in a sample of ~2.5 million biomedical abstracts spanning a 30-year period. Our analyses demonstrate marked growth in terms relating to sex/gender, lifecourse, and socio-economic while racial/ethnic terms have largely plateaued or, in some cases, even declined in usage since the mid-2000s. On the other hand, the use of diversity as well as national, continental, and subcontinental population labels have grown dramatically over the same period. Together, these analyses point to a shift in the way that biomedical researchers enact population differences, relying more on geographical distinctions rather than racial or ethnic classifiers. To better understand how the discourse of diversity relates to this shift in practice, we use word embeddings to study the semantic similarity between these discourses. Our results reveal that diversity becomes less similar to racial/ethnic terms while becoming more similar to sex/gender, lifecourse, and terms used to reference countries in Africa, Oceania and South America. Taken together, this work shows that diversity in biomedical research, rather than addressing racial/ethnic inequity and social justice, is more about the description of the age and gender of research subjects and populations located outside of the major biomedical research hubs in Asia, Europe, and North America. Our findings suggest that the use of diversity, like diversity projects in higher education or employment, are championed as means and goal of doing good science. Such efforts may hinder efforts to address racial inequities that exist in health and science.